{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"is_executing": true,
"name": "#%% md\n"
}
},
"source": [
"# Sample Annotating"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"> **_Google Colab Note:_** If the notebook fails to run after installing the needed packages, try to restart the runtime (Ctrl + M) under Runtime -> Restart session.\n",
"\n",
"[](https://colab.research.google.com/github/scikit-activeml/scikit-activeml.github.io/blob/gh-pages/latest/generated/tutorials_colab//03_pool_oracle_annotations.ipynb)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"**Notebook Dependencies**\n",
"\n",
"Uncomment the following cells to install all dependencies for this tutorial."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [],
"source": [
"# !pip install scikit-activeml\n",
"# !pip install ipyannotations\n",
"# !pip install superintendent\n",
"# !jupyter nbextension install --user --py ipyannotations\n",
"# !jupyter nbextension enable --user --py ipyannotations"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"In supervised and semi-supervised machine learning it is necessary to label data after it was selected by an active learning algorithm. This tutorial shows how to make a simple annotation tool using [ipyannotations](https://ipyannotations.readthedocs.io/en/latest/index.html) and [superintendent](https://superintendent.readthedocs.io/en/latest/index.html). This tutorial requires prior knowledge of our framework. If you are not familiar with it, try some basic [tutorials](https://scikit-activeml.github.io/latest/tutorials.html).\n",
"\n",
"> **_NOTE:_** For testing execute this notebook on your local machine."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [],
"source": [
"import numpy as np\n",
"import math\n",
"from sklearn.model_selection import cross_val_score\n",
"from sklearn.datasets import load_digits\n",
"from sklearn.neural_network import MLPClassifier\n",
"from sklearn.pipeline import Pipeline\n",
"from sklearn.preprocessing import StandardScaler\n",
"\n",
"from skactiveml.utils import is_labeled\n",
"from skactiveml.classifier import SklearnClassifier\n",
"from skactiveml.pool import UncertaintySampling\n",
"\n",
"from superintendent import Superintendent\n",
"from ipywidgets import widgets\n",
"from ipyannotations.images import ClassLabeller\n",
"\n",
"import warnings\n",
"warnings.filterwarnings(\"ignore\")"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## The Annotation Widget Class\n",
"\n",
"At first we define the class `DataLabeler`, which inherits from `Superintendent`. To adapt it to our framework, we have to overwrite the constructor and the methods `_annotation_iterator`, `retrain`, and `_undo`."
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"from skactiveml.utils import unlabeled_indices, call_func\n",
"\n",
"\n",
"class DataLabeler(Superintendent):\n",
" \"\"\"DataLabeler\n",
"\n",
" This class creates a widget for label assignments.\n",
"\n",
" Parameters\n",
" ----------\n",
" X : array-like of shape (n_samples, *)\n",
" Training data set, usually complete, i.e. including the labeled and\n",
" unlabeled samples.\n",
" y : array-like of shape (n_samples,)\n",
" Labels of the training data set (possibly including unlabeled ones\n",
" indicated by self.MISSING_LABEL).\n",
" clf : skactiveml.base.SkactivemlClassifier\n",
" Model implementing the method `fit`. Check `query_strategy` for\n",
" compatibility.\n",
" query_strategy : skactiveml.base.QueryStrategy\n",
" Query strategy used to select the next sample(s) to be labeled.\n",
" labelling_widget : Optional (widgets.Widget)\n",
" An input widget. This needs to follow the interface of the class\n",
" `superintendent.controls.base.SubmissionWidgetMixin`.\n",
" query_dict : dict, default=None\n",
" A dictionary with additional arguments past to `query_strategy`.\n",
" shape_query : Tuple, default=None\n",
" The shape of `X` that is expected of `query_strategy`.\n",
" shape_clf : tuple, default=None\n",
" The shape of `X` that is expected of `clf.fit`.\n",
" batch_size : int, default=1\n",
" The number of samples to be selected in one AL cycle.\n",
" n_cycles : int, default=None\n",
" `n_cycles`*`batch_size` is the maximum number of samples you want to\n",
" annotate. If `None`, the entire dataset is requested for labeling.\n",
" X_eval : array-like of shape (n_eval_samples, n_features), default=None\n",
" Evaluation data set that is used by the `eval_method`. Only used if\n",
" `y_eval` is specified.\n",
" y_eval : array-like of shape (n_eval_samples), default=None\n",
" Labels for the evaluation data set. Only used if `X_eval` is\n",
" specified.\n",
" clf_eval : skactiveml.base.SkactivemlClassifier\n",
" Model implementing the method `fit`, passed to the `eval_method`.\n",
" If None, `clf` is used.\n",
" eval_method : callable\n",
" A function that accepts three arguments - `clf`, `X`, and `y` - and\n",
" returns a validation score of the `clf`. If None,\n",
" `sklearn.model_selection.cross_val_score` is used.\n",
" \"\"\"\n",
" def __init__(\n",
" self,\n",
" X,\n",
" y,\n",
" clf,\n",
" query_strategy,\n",
" labelling_widget,\n",
" query_dict=None,\n",
" shape_query=None,\n",
" shape_clf=None,\n",
" batch_size=1,\n",
" n_cycles=None,\n",
" X_eval=None,\n",
" y_eval=None,\n",
" clf_eval=None,\n",
" eval_method=None,\n",
" **kwargs,\n",
" ):\n",
" # Call the super constructor.\n",
" try:\n",
" super().__init__(\n",
" labelling_widget=labelling_widget,\n",
" eval_method=eval_method,\n",
" **kwargs\n",
" )\n",
" except AttributeError:\n",
" pass\n",
"\n",
" # Assign parameters.\n",
" self.X = X\n",
" self.y = y\n",
" self.clf = clf\n",
" self.shape_query = shape_query\n",
" self.shape_clf = shape_clf\n",
" self.X_eval = X_eval\n",
" self.y_eval = y_eval\n",
" self.clf_eval = clf_eval or clf\n",
" self.query_dict = query_dict or {}\n",
" self.batch_size = batch_size\n",
" self.query_strategy = query_strategy\n",
" self.n_cycles = n_cycles or math.ceil(len(X)/batch_size)\n",
"\n",
" self.labeled_indices = []\n",
" self.labels = []\n",
" self.candidates = unlabeled_indices(y)\n",
"\n",
" # Generate the widgets.\n",
" self.model_performance = widgets.HTML(value=\"\")\n",
" self.top_bar = widgets.HBox(\n",
" [\n",
" widgets.HBox(\n",
" [self.progressbar],\n",
" layout=widgets.Layout(width=\"50%\",\n",
" justify_content=\"space-between\"),\n",
" ),\n",
" widgets.HBox(\n",
" [self.model_performance],\n",
" layout=widgets.Layout(width=\"50%\"),\n",
" ),\n",
" ]\n",
" )\n",
" self.children = [self.top_bar, self.labelling_widget]\n",
"\n",
" # Start the annotation loop.\n",
" self._begin_annotation()\n",
"\n",
" def _annotation_iterator(self):\n",
" \"\"\"The annotation loop.\"\"\"\n",
" self.children = [self.top_bar, self.labelling_widget]\n",
" self.progressbar.bar_style = \"\"\n",
" # Fit the clf\n",
" self.retrain()\n",
" i = 0\n",
" y = None\n",
" while i < self.n_cycles:\n",
" # Query the next batch of samples.\n",
" self.query_dict[\"X\"] = self.X.reshape(self.shape_query)\n",
" idx = call_func(self.query_strategy.query,\n",
" y=self.y,\n",
" clf=self.clf,\n",
" reg=self.clf,\n",
" ensemble=self.clf,\n",
" candidates=self.candidates,\n",
" batch_size=self.batch_size,\n",
" **self.query_dict)\n",
" j = 0\n",
" if y == 'undo':\n",
" j = self.batch_size-1\n",
" if self.batch_size != 1:\n",
" self.y[self.labeled_indices[-j:]] = self.labels[-j:]\n",
" self.candidates = np.delete(\n",
" self.candidates,\n",
" self.labeled_indices[-j:]\n",
" )\n",
" while j 0:\n",
" self._annotation_loop.send('undo') # Advance next item\n",
"\n",
"\n",
" def retrain(self, button=None):\n",
" \"\"\"Re-train the `clf` you passed when creating this widget.\n",
"\n",
" This calls the `fit` method of your `clf` with the data that you've\n",
" labeled. It will also score the classifier and display the\n",
" performance.\n",
"\n",
" Parameters\n",
" ----------\n",
" button : widget.Widget, optional\n",
" Optional & ignored; this is passed when invoked by a button.\n",
" \"\"\"\n",
" with self._render_hold_message(\"Retraining...\"):\n",
" if self.X_eval is not None:\n",
" X_eval = self.X_eval\n",
" y_eval = self.y_eval\n",
" else:\n",
" X_eval = self.X[is_labeled(self.y)]\n",
" y_eval = self.y[is_labeled(self.y)]\n",
" shape_clf = (len(X_eval), *self.shape_clf[1:])\n",
"\n",
" # Fit the clf.\n",
" try:\n",
" self.clf.fit(self.X.reshape(self.shape_clf), self.y)\n",
" except ValueError as e:\n",
" if str(e).startswith(\n",
" \"This solver needs samples of at least 2\"\n",
" ):\n",
" self.model_performance.value = \\\n",
" \"Not enough classes to retrain.\"\n",
" return\n",
" else:\n",
" raise\n",
"\n",
" # Evaluate the clf. By default, using cross validation.\n",
" # In sklearn this clones the clf, so it's OK to do after the clf\n",
" # fit.\n",
" try:\n",
" if self.eval_method is not None:\n",
" performance = np.mean(\n",
" self.eval_method(\n",
" self.clf_eval,\n",
" X_eval.reshape(shape_clf),\n",
" y_eval\n",
" )\n",
" )\n",
" else:\n",
" performance = np.mean(\n",
" cross_val_score(\n",
" self.clf_eval,\n",
" X_eval.reshape(shape_clf),\n",
" y_eval,\n",
" cv=3,\n",
" error_score=np.nan\n",
" )\n",
" )\n",
" except ValueError as e:\n",
" if \"n_splits=\" in str(e) \\\n",
" or \"Found array with 0 sample(s)\" in str(e) \\\n",
" or \"cannot reshape array of size 0\" in str(e):\n",
" self.model_performance.value = \\\n",
" \"Not enough labels to evaluate.\"\n",
" return\n",
" else:\n",
" raise\n",
"\n",
" self.model_performance.value = f\"Score: {performance:.3f}\""
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## Create Dataset\n",
"For this tutorial we use the digit data set available through the `sklearn` package. The 8x8 images show handwritten digits from 0 to 9."
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [],
"source": [
"X = load_digits().data.reshape(-1, 8, 8)\n",
"y = np.full(shape=len(X), fill_value=np.nan)"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"## Create and Start Annotation Process\n",
"\n",
"As classifier, `MLPClassifier` and `StandardScaler` by `sklearn` is used in a pipeline and `UncertaintySampling` from our framework `Skactiveml` as query strategy. `ClassLabeller` creates a ipywidget, which displays the selected sample and provides the labelling interface for the user. This class can be exchanged by [other widgets](https://ipyannotations.readthedocs.io/en/latest/widget-list.html) to support different types of data. The `DataLabeler`-widget manages the iteration over the data set."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"pycharm": {
"name": "#%%\n"
}
},
"outputs": [],
"source": [
"random_state = 42\n",
"pipe = Pipeline([('scaler', StandardScaler()), ('MLP', MLPClassifier(random_state=random_state))])\n",
"clf = SklearnClassifier(pipe, classes=range(10), random_state=random_state)\n",
"\n",
"qs = UncertaintySampling(random_state=random_state)\n",
"\n",
"labelling_widget = ClassLabeller(\n",
" options=list(range(0, 10)), image_size=(100, 100)\n",
")\n",
"\n",
"data_labeler = DataLabeler(\n",
" X=X,\n",
" y=y,\n",
" clf=clf,\n",
" shape_query=(len(X), -1),\n",
" shape_clf=(len(X), -1),\n",
" query_strategy=qs,\n",
" labelling_widget=labelling_widget,\n",
" batch_size=2,\n",
" n_cycles=50\n",
")\n",
"data_labeler"
]
},
{
"cell_type": "markdown",
"metadata": {
"pycharm": {
"name": "#%% md\n"
}
},
"source": [
"The cell above produces an output which looks like the following image.\n",
"\n",
"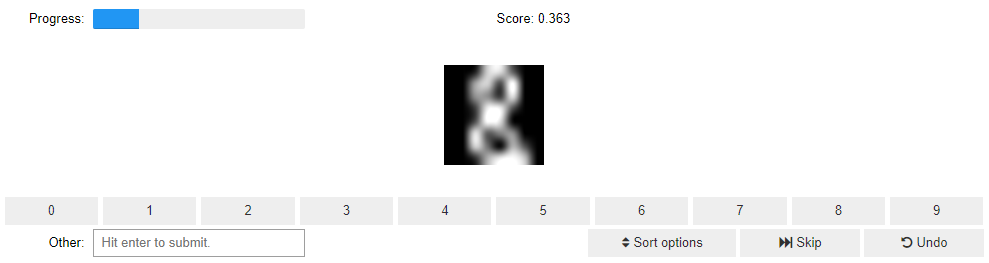"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "skaml",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.12.9"
}
},
"nbformat": 4,
"nbformat_minor": 1
}