Multi-annotator Pool-based Active Learning - Getting Started#
This notebook gives an introduction for dealing with multiple annotators using skactiveml.
[1]:
import matplotlib as mlp
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
from skactiveml.classifier import ParzenWindowClassifier
from skactiveml.pool import ProbabilisticAL
from skactiveml.pool.multiannotator import SingleAnnotatorWrapper
from skactiveml.utils import MISSING_LABEL, majority_vote
from skactiveml.visualization import plot_decision_boundary, plot_annotator_utilities
mlp.rcParams["figure.facecolor"] = "white"
FONTSIZE = 20
MARKER_SIZE = 100
Data Set Generation#
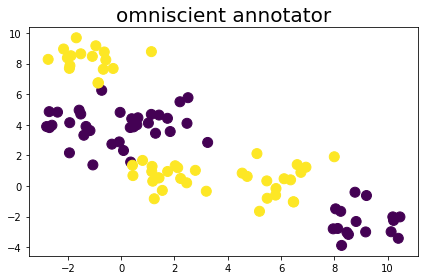
Suppose we have 100 two-dimensional samples belonging to one of two classes. To generate the example problem, we use the make_blobs function by sklearn.
[2]:
n_samples = 100
X, y_true = make_blobs(
n_samples=n_samples, centers=6, random_state=0
)
bound = [[min(X[:, 0]), min(X[:, 1])], [max(X[:, 0]), max(X[:, 1])]]
y_true %= 2
fig, ax = plt.subplots(1, 1)
ax.scatter(X[:, 0], X[:, 1], c=y_true, s=MARKER_SIZE)
ax.set_title("omniscient annotator", fontsize=FONTSIZE)
fig.tight_layout()
plt.show()
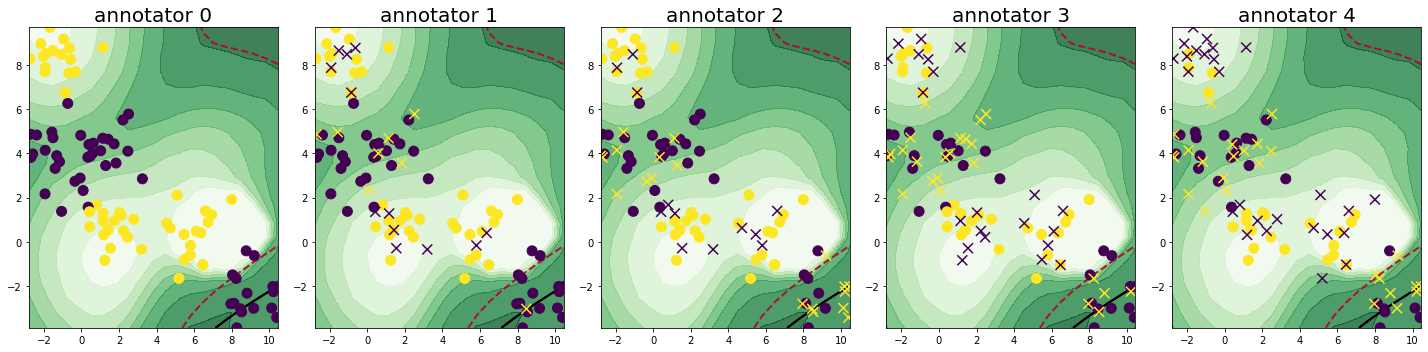
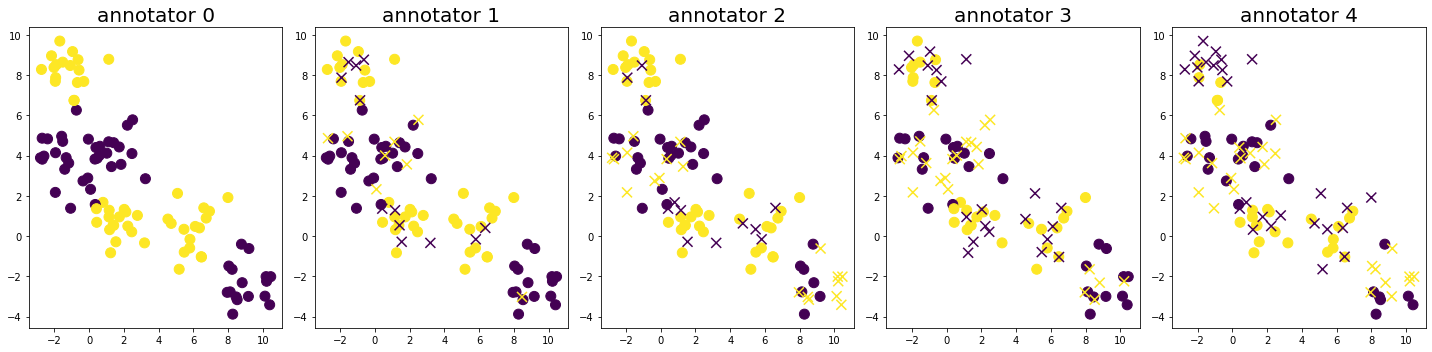
Further, suppose we have 5 annotators to label the samples. The annotators have different accuracies for labeling the samples. The plot below visualizes the obtained labels from each annotator, where the color indicates the provided class label and the shape whether the label is correct (circle) or false (cross).
[3]:
rng = np.random.default_rng(seed=0)
n_annotators = 5
y_annot = np.zeros(shape=(n_samples, n_annotators), dtype=int)
for i, p in enumerate(np.linspace(0.0, 0.5, num=n_annotators)):
y_noise = rng.binomial(1, p, n_samples)
y_annot[:, i] = y_noise ^ y_true
fig, axes = plt.subplots(1, n_annotators, figsize=(20, 5))
for a in range(n_annotators):
is_true = y_annot[:, a] == y_true
axes[a].scatter(X[is_true, 0], X[is_true, 1], c=y_annot[is_true, a], s=MARKER_SIZE)
axes[a].scatter(X[~is_true, 0], X[~is_true, 1], c=y_annot[~is_true, a], marker='x', s=MARKER_SIZE)
axes[a].set_title(f'annotator {a}', fontsize=FONTSIZE)
fig.tight_layout()
plt.show()
Active Classification#
We want to label these samples using a ParzenWindowClassifier. We query the samples using uncertainty sampling, and the annotators at random using the SingleAnnotWrapper. To achieve this, we first pass the ParzenWindowClassifier as an argument to the single annotator query strategy ProbabilisticAL. Then we pass the single annotator query strategy as an argument to the wrapper, also specifying the number of annotators.
[4]:
clf = ParzenWindowClassifier(
classes=np.unique(y_true),
metric="rbf",
metric_dict={"gamma": 0.1},
class_prior=0.001,
random_state=0,
)
sa_qs = ProbabilisticAL(random_state=0, prior=0.001)
ma_qs = SingleAnnotatorWrapper(sa_qs, random_state=0)
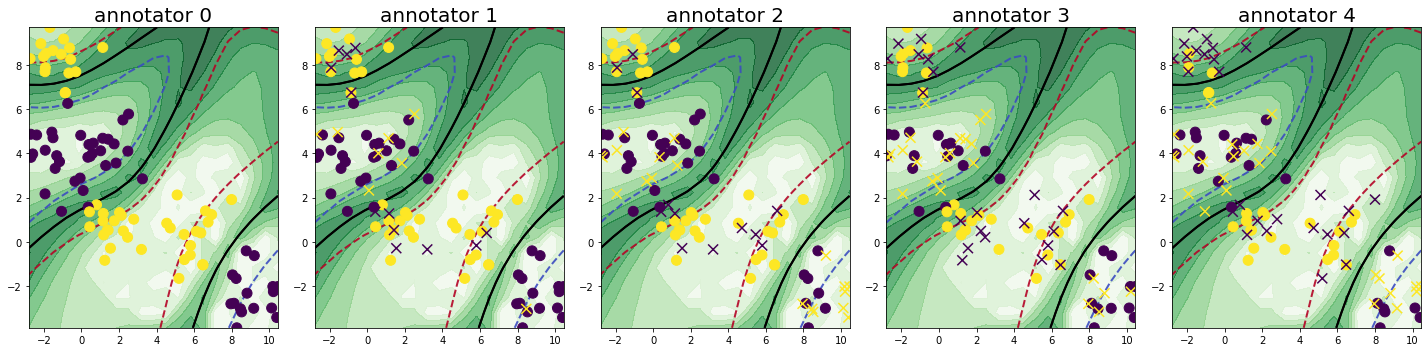
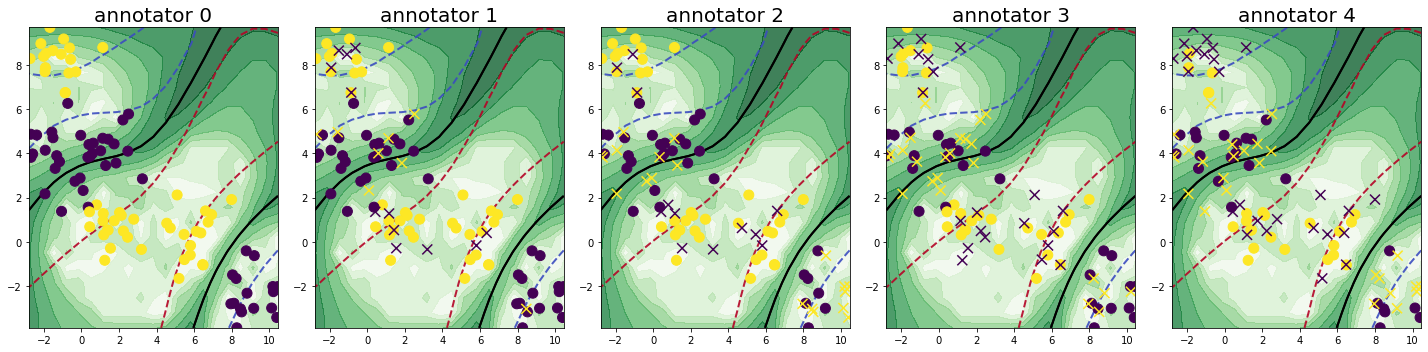
We loop through the process of querying samples and annotators over a total of 20 cycles. Each iteration, we query three annotators for one sample, setting the batch size and the number of annotators per sample to three. We set the candidate annotators for each sample to be those, who have not already labeled the given sample. Further, we fit our classifier using the majority votes of the queried labels. The results are displayed after the 5th, the 14th, and the 20th cycle. The assigned utilities of the query strategy for labeling a sample annotator pair are displayed by the saturation of the green color in the plot and the classifiers decision boundary is given by the black line.
[5]:
# function to be able to index via an array of indices
idx = lambda A: (A[:, 0], A[:, 1])
n_cycle = 20
# the already observed labels for each sample and annotator
y = np.full(shape=(n_samples, n_annotators), fill_value=MISSING_LABEL)
clf.fit(X, majority_vote(y))
for c in range(n_cycle):
# the needed query parameters for the wrapped single annotator query strategy
query_params_dict = {"clf": clf}
query_idx = ma_qs.query(
X,
y,
batch_size=3,
n_annotators_per_sample=3,
query_params_dict=query_params_dict,
)
y[idx(query_idx)] = y_annot[idx(query_idx)]
clf.fit(X, majority_vote(y, random_state=0))
if c in [4, 13, 19]:
ma_qs_arg_dict = {"query_params_dict": query_params_dict}
fig, axes = plt.subplots(1, n_annotators, figsize=(20, 5))
axes = plot_annotator_utilities(ma_qs, X=X, y=y, query_params_dict={'clf': clf}, axes=axes, feature_bound=bound)
for a in range(n_annotators):
plot_decision_boundary(clf, ax=axes[a], feature_bound=bound)
is_true = y_annot[:, a] == y_true
axes[a].scatter(X[is_true, 0], X[is_true, 1], c=y_annot[is_true, a], s=MARKER_SIZE)
axes[a].scatter(X[~is_true, 0], X[~is_true, 1], c=y_annot[~is_true, a], marker='x', s=MARKER_SIZE)
axes[a].set_title(f'annotator {a}', fontsize=FONTSIZE)
fig.tight_layout()
plt.show()