Pool-based Active Learning - Getting Started#
Google Colab Note: If the notebook fails to run after installing the needed packages, try to restart the runtime (Ctrl + M) under Runtime -> Restart session.
![]()
Notebook Dependencies
Uncomment the following cell to install all dependencies for this tutorial.
[1]:
# !pip install scikit-activeml
The main purpose of this tutorial is to ease the implementation of our library scikit-activeml to new users. scikit-activeml is a library that executes the most important query strategies. It is built upon the well-known machine learning frame-work scikit-learn, which makes it user-friendly. For better understanding, we show an exemplary active learning cycle here. Let’s start by importing the relevant packages from both scikit-learn and scikit-activeml.
[2]:
import numpy as np
import matplotlib as mlp
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
from skactiveml.classifier import SklearnClassifier
from skactiveml.pool import UncertaintySampling
from skactiveml.utils import unlabeled_indices, labeled_indices, MISSING_LABEL
from skactiveml.visualization import plot_decision_boundary, plot_utilities
import warnings
mlp.rcParams["figure.facecolor"] = "white"
warnings.filterwarnings("ignore")
Data Set Generation#
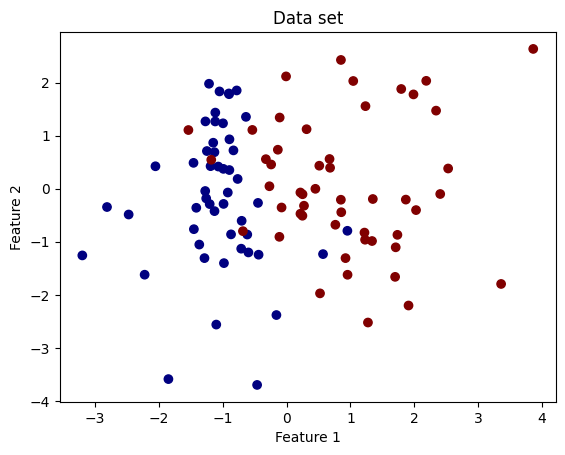
We generate a data set of 100 data points with two clusters from the make_classification method of scikit-learn. This method also returns the true labels of each data point. In practice, however, we do not know these labels unless we ask an oracle. The labels are stored in y_true, which acts as an oracle.
[3]:
X, y_true = make_classification(n_features=2, n_redundant=0, random_state=0)
bound = [[min(X[:, 0]), min(X[:, 1])], [max(X[:, 0]), max(X[:, 1])]]
plt.scatter(X[:, 0], X[:, 1], c=y_true, cmap='jet')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Data set');
Classification#
Our goal is to classify the data points into two classes. To do so, we introduce a vector y to store the labels that we acquire from the oracle (y_true). As shown below, the vector y is unlabeled at the beginning.
[4]:
y = np.full(shape=y_true.shape, fill_value=MISSING_LABEL)
print(y)
[nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan
nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan
nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan
nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan
nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan nan
nan nan nan nan nan nan nan nan nan nan]
There are many easy-to-use classification algorithms in scikit-learn. In this example, we use the logistic regression classifier. Details of other classifiers can be accessed from here. As scikit-learn classifiers cannot cope with missing labels, we need to wrap these with the SklearnClassifier.
[5]:
clf = SklearnClassifier(LogisticRegression(), classes=np.unique(y_true))
Query Strategy#
The query strategies are the central part of our library. In this example, we use uncertainty sampling with entropy to determine the most uncertain data points. All implemented strategies can be accessed from here.
[6]:
qs = UncertaintySampling(method='entropy', random_state=42)
Active Learning Cycle#
In this example, we perform 20 iterations of the active learning cycle (n_cycles=20). In each iteration, we select one unlabeled sample to be labeled (batch_size=1). The sample is selected by an index (query_idx).
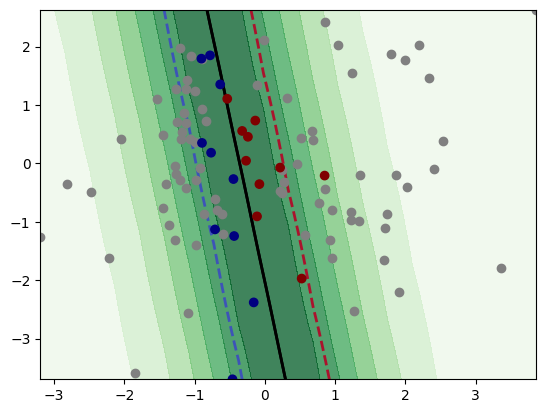
The label is acquired by assigning the label from y_true to y. Then, we retrain our classifier. We continue until we reach the 20 labeled data points. Below, we see the implementation of an active learning cycle. The first figure shows the decision boundary after acquiring the label of two data points. The second figure shows the decision boundary with 10 acquired labels, which shows significant improvement compared to the first figure. The last figure shows the decision boundary after
acquiring labels for 20 data points. Finally, we use the accuracy score as a performance measure, which shows the accuracy of our classifier in the specified iterations.
[7]:
n_cycles = 20
y = np.full(shape=y_true.shape, fill_value=MISSING_LABEL)
clf.fit(X, y)
for c in range(n_cycles):
query_idx = qs.query(X=X, y=y, clf=clf, batch_size=1)
y[query_idx] = y_true[query_idx]
clf.fit(X, y)
# plotting
unlbld_idx = unlabeled_indices(y)
lbld_idx = labeled_indices(y)
if len(lbld_idx) in [2, 10, 20]:
print(f'After {len(lbld_idx)} iterations:')
print(f'The accuracy score is {clf.score(X,y_true)}.')
plot_utilities(qs, X=X, y=y, clf=clf, feature_bound=bound)
plot_decision_boundary(clf, feature_bound=bound)
plt.scatter(X[unlbld_idx,0], X[unlbld_idx,1], c='gray')
plt.scatter(X[:,0], X[:,1], c=y, cmap='jet')
plt.show()
After 2 iterations:
The accuracy score is 0.68.
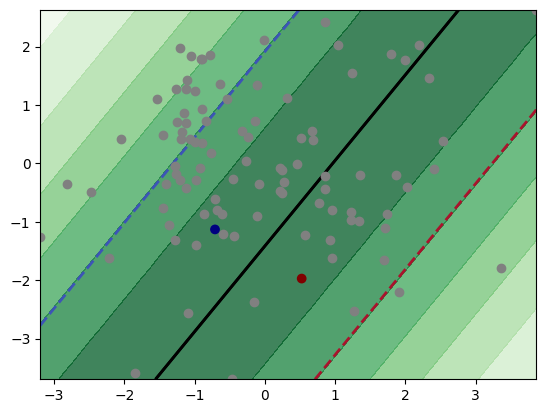
After 10 iterations:
The accuracy score is 0.95.
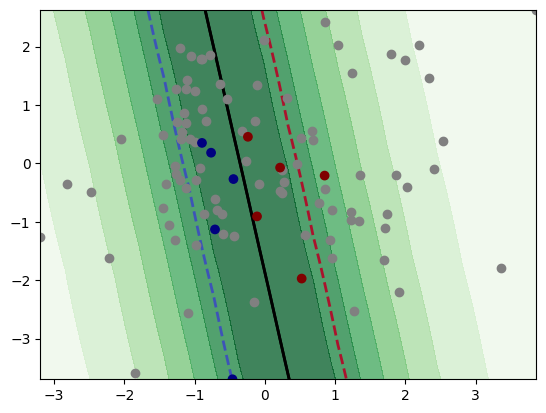
After 20 iterations:
The accuracy score is 0.95.