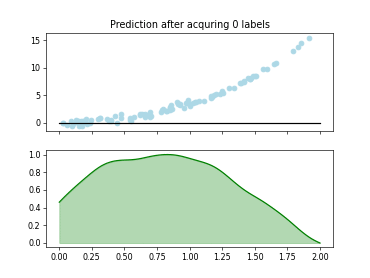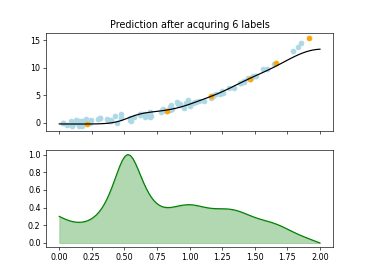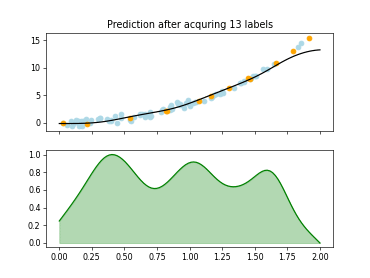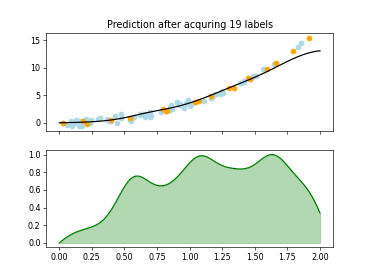
skactiveml.pool.ExpectedModelOutputChange#
- class skactiveml.pool.ExpectedModelOutputChange(integration_dict=None, loss=None, missing_label=nan, random_state=None)[source]#
Bases:
SingleAnnotatorPoolQueryStrategyRegression based Expected Model Output Change.
This class implements an expected model output change based approach for regression, where samples are queried that change the output of the model the most.
- Parameters
- integration_dictdict, optional (default=None)
Dictionary for integration arguments, i.e. integration_method etc., used for calculating the expected y value for the candidate samples. For details see method skactiveml.pool.utils._conditional_expect. The default integration_method is assume_linear.
- losscallable, optional (default=None)
The loss for predicting a target value instead of the true value. Takes in the predicted values of an evaluation set and the true values of the evaluation set and returns the error, a scalar value. The default loss is sklearn.metrics.mean_squared_error an alternative might be sklearn.metrics.mean_absolute_error.
- missing_labelscalar or string or np.nan or None,
- (default=skactiveml.utils.MISSING_LABEL)
Value to represent a missing label.
- random_stateint | np.random.RandomState, optional (default=None)
Random state for candidate selection.
References
- [1] Christoph Kaeding, Erik Rodner, Alexander Freytag, Oliver Mothes,
Oliver, Bjoern Barz and Joachim Denzler. Active Learning for Regression Tasks with Expected Model Output Change, BMVC, page 1-15, 2018.
Methods
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
query(X, y, reg[, fit_reg, sample_weight, ...])Determines for which candidate samples labels are to be queried.
set_params(**params)Set the parameters of this estimator.
- get_metadata_routing()#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)#
Get parameters for this estimator.
- Parameters
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns
- paramsdict
Parameter names mapped to their values.
- query(X, y, reg, fit_reg=True, sample_weight=None, candidates=None, X_eval=None, batch_size=1, return_utilities=False)[source]#
Determines for which candidate samples labels are to be queried.
- Parameters
- Xarray-like of shape (n_samples, n_features)
Training data set, usually complete, i.e. including the labeled and unlabeled samples.
- yarray-like of shape (n_samples)
Labels of the training data set (possibly including unlabeled ones indicated by self.missing_label).
- regProbabilisticRegressor
Predicts the output and the target distribution.
- fit_regbool, optional (default=True)
Defines whether the regressor should be fitted on X, y, and sample_weight.
- sample_weightarray-like of shape (n_samples), optional
- (default=None)
Weights of training samples in X.
- candidatesNone or array-like of shape (n_candidates), dtype=int or
array-like of shape (n_candidates, n_features), optional (default=None) If candidates is None, the unlabeled samples from (X,y) are considered as candidates. If candidates is of shape (n_candidates) and of type int, candidates is considered as the indices of the samples in (X,y). If candidates is of shape (n_candidates, n_features), the candidates are directly given in candidates (not necessarily contained in X).
- X_evalarray-like of shape (n_eval_samples, n_features),
- optional (default=None)
Evaluation data set that is used for estimating the probability distribution of the feature space. In the referenced paper it is proposed to use the unlabeled data, i.e. X_eval=X[is_unlabeled(y)].
- batch_sizeint, optional (default=1)
The number of samples to be selected in one AL cycle.
- return_utilitiesbool, optional (default=False)
If true, also return the utilities based on the query strategy.
- Returns
- query_indicesnumpy.ndarray of shape (batch_size)
The query_indices indicate for which candidate sample a label is to queried, e.g., query_indices[0] indicates the first selected sample. If candidates is None or of shape (n_candidates), the indexing refers to samples in X. If candidates is of shape (n_candidates, n_features), the indexing refers to samples in candidates.
- utilitiesnumpy.ndarray of shape (batch_size, n_samples) or
numpy.ndarray of shape (batch_size, n_candidates) The utilities of samples after each selected sample of the batch, e.g., utilities[0] indicates the utilities used for selecting the first sample (with index query_indices[0]) of the batch. Utilities for labeled samples will be set to np.nan. If candidates is None or of shape (n_candidates), the indexing refers to samples in X. If candidates is of shape (n_candidates, n_features), the indexing refers to samples in candidates.
- set_params(**params)#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters
- **paramsdict
Estimator parameters.
- Returns
- selfestimator instance
Estimator instance.