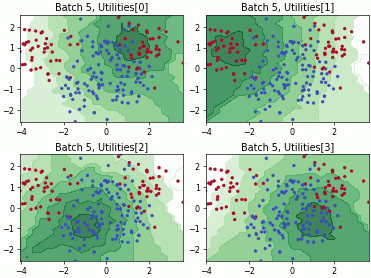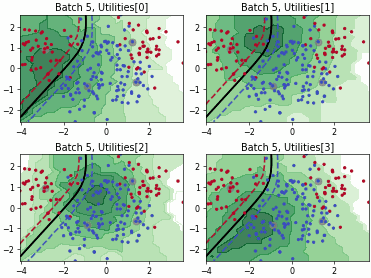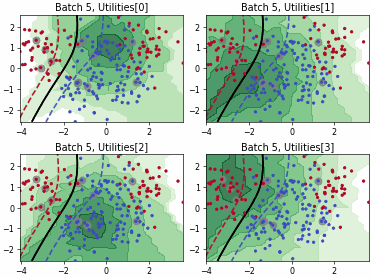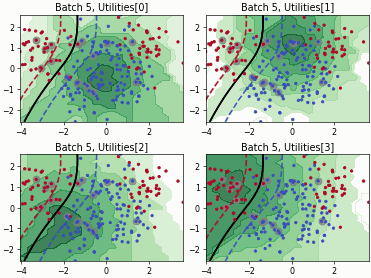
Clue#
- class skactiveml.pool.Clue(predict_dict=None, method='entropy', cluster_algo=<class 'sklearn.cluster._kmeans.KMeans'>, cluster_algo_dict=None, n_cluster_param_name='n_clusters', missing_label=nan, random_state=None)[source]#
Bases:
SingleAnnotatorPoolQueryStrategyClustering Uncertainty-weighted Embeddings (CLUE)
This class implements the Clustering Uncertainty-weighted Embeddings (CLUE) query strategy [1] clusters latent embeddings while weighting samples by predictive uncertainty, then picks samples near the cluster centers. The result is a diverse set biased toward uncertain regions of representation space.
The original Clue query strategy was proposed for classification tasks only and did not include a regression variant. Support for regression in this implementation is therefore an extension of the original formulation and relies on user-provided sample-wise uncertainty estimates.
- Parameters:
- predict_dictdict or None, default=None
Optional keyword arguments passed to the estimator’s prediction method in order to obtain sample embeddings and/or uncertainties as additional outputs.
For classification, Clue calls:
out = estimator.predict_proba(X, **predict_dict)
For regression, Clue calls:
out = estimator.predict(X, **predict_dict)
If out is a tuple, its additional elements are inferred by shape: sample-wise uncertainties must be a 1D numpy.ndarray, and sample embeddings must be a 2D numpy.ndarray.
In the classification case, returning uncertainties is optional, because they can be derived from the predicted class probabilities (see the documentation of the method parameter). In the regression case, providing uncertainties as an additional output is mandatory.
- method‘least_confident’ or ‘margin_sampling’ or ‘entropy’, default=”entropy”
Fallback uncertainty measure used in the classification case when the classifier does not provide explicit uncertainties.
method=’least_confident’ queries the sample whose maximal posterior probability is minimal.
method=’margin_sampling’ queries the sample whose posterior probability gap between the most and the second most probable class label is minimal.
method=’entropy’ queries the sample whose posterior’s have the maximal entropy.
- cluster_algoClusterMixin.__class__, default=KMeans
The cluster algorithm to be used. It must implement a fit_transform method, which takes samples X and sample_weight as inputs, e.g., sklearn.clustering.KMeans and sklearn.clustering.MiniBatchKMeans.
- cluster_algo_dictdict, default=None
The parameters passed to the clustering algorithm cluster_algo, excluding the parameter for the number of clusters.
- n_cluster_param_namestring, default=”n_clusters”
The name of the parameter for the number of clusters.
- missing_labelscalar or string or np.nan or None, default=np.nan
Value to represent a missing label.
- random_stateNone or int or np.random.RandomState, default=None
The random state to use.
References
[1]V. Prabhu, A. Chandrasekaran, K. Saenko, and J. Hoffman. Active domain adaptation via clustering uncertainty-weighted embeddings. In IEEE/CVF Int. Conf. Comput. Vis., pages 8505–8514, 2021.
Methods
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
query(X, y, estimator[, fit_estimator, ...])Determines for which candidate samples labels are to be queried.
set_params(**params)Set the parameters of this estimator.
- get_metadata_routing()#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- query(X, y, estimator, fit_estimator=True, sample_weight=None, candidates=None, batch_size=1, return_utilities=False)[source]#
Determines for which candidate samples labels are to be queried.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Training data set, usually complete, i.e., including the labeled and unlabeled samples.
- yarray-like of shape (n_samples,)
Labels of the training data set (possibly including unlabeled ones indicated by self.missing_label).
- estimatorskactiveml.base.SkactivemlClassifier or skactiveml.base.SkactivemlRegressor
Estimator implementing the methods fit and predict_proba (classification) or predict (regression).
- fit_estimatorbool, default=True
Defines whether the estimator should be fitted on X, y, and sample_weight.
- sample_weight: array-like of shape (n_samples,), default=None
Weights of training samples in X.
- candidatesNone or array-like of shape (n_candidates,), dtype=int or array-like of shape (n_candidates, n_features), default=None
If candidates is None, the unlabeled samples from (X,y) are considered as candidates.
If candidates is of shape (n_candidates,) and of type int, candidates is considered as the indices of the samples in (X,y).
- batch_sizeint, default=1
The number of samples to be selected in one AL cycle.
- return_utilitiesbool, default=False
If True, also return the utilities based on the query strategy.
- Returns:
- query_indicesnumpy.ndarray of shape (batch_size,)
The query indices indicate for which candidate sample a label is to be queried, e.g., query_indices[0] indicates the first selected sample. The indexing refers to the samples in X.
- utilitiesnumpy.ndarray of shape (batch_size, n_samples) or numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch, e.g., utilities[0] indicates the utilities used for selecting the first sample (with index query_indices[0]) of the batch. Utilities for labeled samples will be set to np.nan. The indexing refers to the samples in X.
- set_params(**params)#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.