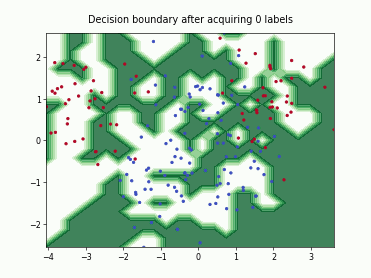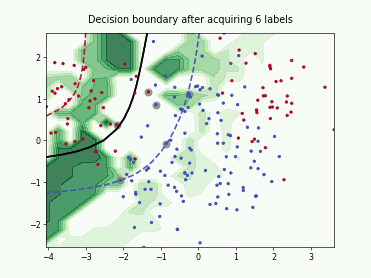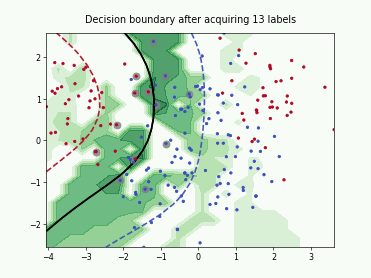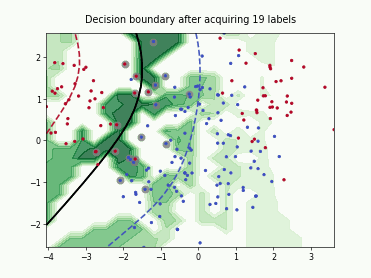
SubSamplingWrapper#
- class skactiveml.pool.SubSamplingWrapper(query_strategy=None, max_candidates=0.1, exclude_non_subsample=False, embed_samples_func=None, missing_label=nan, random_state=None)[source]#
Bases:
SingleAnnotatorPoolQueryStrategySub-sampling Wrapper
This class implements a wrapper for single-annotator pool-based strategies that randomly sub-samples a set of candidates before computing their utilities. This is useful when the number of available candidates is too large and a small subset of candidates is sufficient to select a good batch for labeling. The number of candidates can be controlled using max_candidates which supports an absolute number or a fraction of the available candidates. Additionally, exclude_non_subsample provides an option to mask all candidates that were not included in the subsample. This can further improve the runtime for query strategies that utilize all available unlabeled data in their selection.
- Parameters:
- query_strategyskactiveml.base.SingleAnnotatorPoolQueryStrategy
The strategy used for computing the utilities of the candidate sub-sample.
- max_candidatesint or float, default=0.1
Determines the number of candidates. If max_candidates is an integer, max_candidates is the maximum number of candidates whose utilities are computed. If max_candidates is a float, max_candidates is the fraction of the original number of candidates.
- exclude_non_subsamplebool, default=False
If True, unlabeled candidates in X and y are excluded which are not part of the subsample. If candidates is an array-like of shape (n_candidates, n_features), all unlabeled data will be removed from X and y.
If False, X and y stay the same.
- embed_samples_funcCallable or None, default=None
If embed_samples_func is a Callable, it must accept the samples X as input and return the sample-wise embeddings.
If embed_samples_func is None, no action is performed.
- missing_labelscalar or string or np.nan or None, default=np.nan
Value to represent a missing label.
- random_stateint or np.random.RandomState, default=None
The random state to use.
Methods
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
query(X, y[, candidates, batch_size, ...])Determines for which candidate samples labels are to be queried.
set_params(**params)Set the parameters of this estimator.
- get_metadata_routing()#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
- routingMetadataRequest
A
MetadataRequestencapsulating routing information.
- get_params(deep=True)#
Get parameters for this estimator.
- Parameters:
- deepbool, default=True
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns:
- paramsdict
Parameter names mapped to their values.
- query(X, y, candidates=None, batch_size=1, return_utilities=False, **query_kwargs)[source]#
Determines for which candidate samples labels are to be queried.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
Training data set, usually complete, i.e., including the labeled and unlabeled samples.
- yarray-like of shape (n_samples,)
Labels of the training data set (possibly including unlabeled ones indicated by self.MISSING_LABEL).
- candidatesNone or array-like of shape (n_candidates), dtype=int or array-like of shape (n_candidates, n_features), default=None
If candidates is None, the unlabeled samples from (X,y) are considered as candidates.
If candidates is of shape (n_candidates,) and of type int, candidates is considered as the indices of the samples in (X,y).
If candidates is of shape (n_candidates, …), the candidate samples are directly given in candidates (not necessarily contained in X). This is not supported by all query strategies.
- batch_sizeint, default=1
The number of samples to be selected in one AL cycle.
- return_utilitiesbool, default=False
If True, also return the utilities based on the query strategy.
- **query_kwargsdict-like
Further keyword arguments are passed to the query method of the query_strategy object.
- Returns:
- query_indicesnumpy.ndarray of shape (batch_size,)
The query indices indicate for which candidate sample a label is to be queried, e.g., query_indices[0] indicates the first selected sample.
If candidates is None or of shape (n_candidates,), the indexing refers to the samples in X.
If candidates is of shape (n_candidates, n_features), the indexing refers to the samples in candidates.
- utilitiesnumpy.ndarray of shape (batch_size, n_samples) or numpy.ndarray of shape (batch_size, n_candidates)
The utilities of samples after each selected sample of the batch, e.g., utilities[0] indicates the utilities used for selecting the first sample (with index query_indices[0]) of the batch. Utilities for labeled samples will be set to np.nan.
If candidates is None or of shape (n_candidates,), the indexing refers to the samples in X.
If candidates is of shape (n_candidates, n_features), the indexing refers to the samples in candidates.
- set_params(**params)#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **paramsdict
Estimator parameters.
- Returns:
- selfestimator instance
Estimator instance.